
 MVP Profile
MVP Profile
 Try my app HoloATC!
Try my app HoloATC!  HoloLens 2
HoloLens 2
 Magic Leap 2
Magic Leap 2
 Android phones
Android phones
 Snap Spectacles
Snap Spectacles
 Buy me a drink ;)
Buy me a drink ;)
 BlueSky
BlueSky
 Mastodon
Mastodon
 Discord: LocalJoost#3562
Discord: LocalJoost#3562
MRTK2 to MRTK3 - simple global speech recognition
Updated December 6, 2023
So, in ye olden days, you defined your speech command input in the MRTK Speech Command Profile, then somewhere in your scene you put a SpeechInputHandler, and configured methods that should be executed upon the phrases being recognized. No trace of all of that in MRTK3. The only thing I could find was SpeechInteractor and to be honest, I have yet to get a clear idea what that is for, or how to use it. In the mean time, I really wanted to use global speech commands. And I did. With a little help from a script.
So how does speech recognition work now?
Digging into the MRTK3 code, beneath some layers of code, I found code that, when all is said and done, boiled down to this:
phraseRecognitionSubsystem.CreateOrGetEventForKeyword("keyword").
AddListener(SomeMethod);
So how to get a reference to the Phrase Recognition Subsystem?
var phraseRecognitionSubsystem =
XRSubsystemHelpers.KeywordRecognitionSubsystem;
Of course, to enable speech recognition, you will need to select the Phrase Recognition Subsystem in the MRTK3 configuration profile
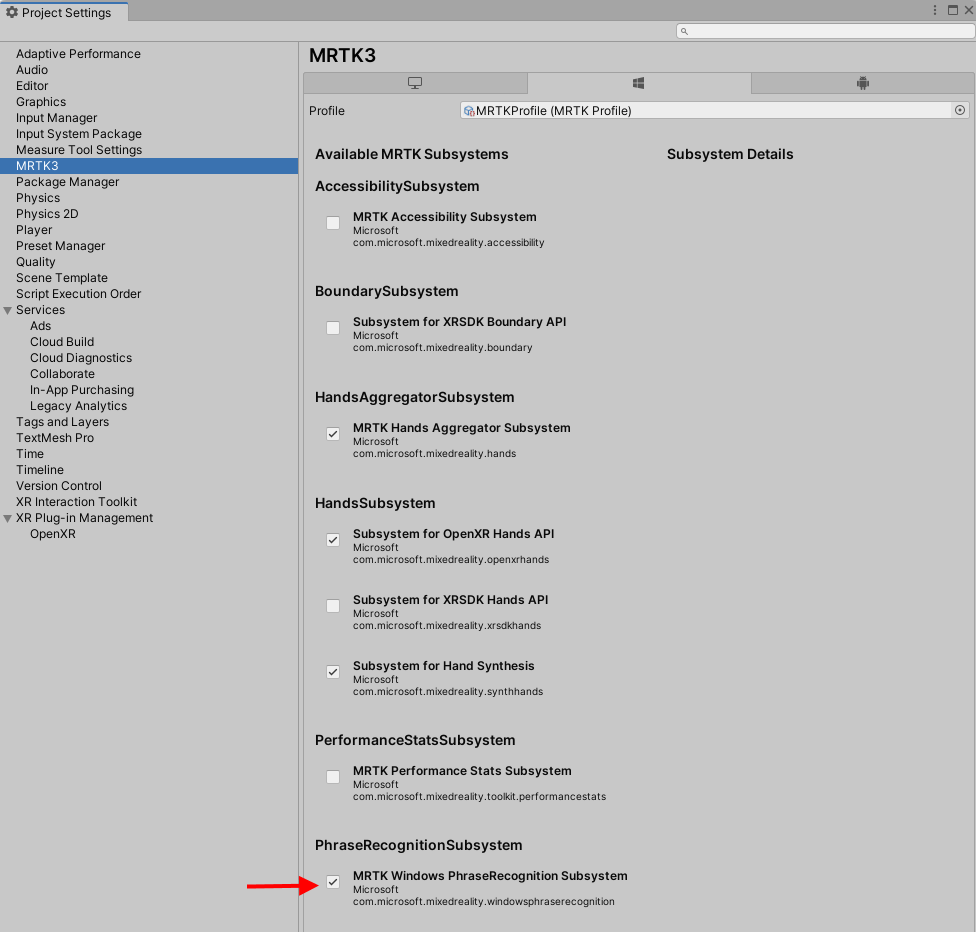
And that, my dear reader, is basically all the knowledge you need to have to get global speech recognition going.
Resurrecting SpeechInputHandler - sort of
To make your life even more simple, I crafted this little behaviour that has all the stuff in it you need to simply configure what phrases to recognize and what methods need to be called upon recognition. In the editor. Just like in the old days. I could not resist calling it SpeechInputHandler too :D.
But first, a little helper to define phrases and actions:
[Serializable]
public struct PhraseAction
{
[SerializeField]
private string phrase;
[SerializeField]
private UnityEvent action;
public string Phrase => phrase;
public UnityEvent Action => action;
}
Then the basic SpeechInputHandler itself
public class SpeechInputHandler : MonoBehaviour
{
[SerializeField]
private List<PhraseAction> phraseActions;
private void Start()
{
var phraseRecognitionSubsystem =
XRSubsystemHelpers.KeywordRecognitionSubsystem;
foreach (var phraseAction in phraseActions)
{
if (!string.IsNullOrEmpty(phraseAction.Phrase) &&
phraseAction.Action.GetPersistentEventCount() > 0)
{
phraseRecognitionSubsystem.
CreateOrGetEventForKeyword(phraseAction.Phrase).
AddListener(() => phraseAction.Action.Invoke());
}
}
}
}
This simply creates a listener for each recognized phrase, that invokes the accompanying event defined in Action, thereby invoking all the listeners to that event. I added a little validation code to fish out phrases that are defined more than once time, this does not really work in global speech recognition:
private void OnValidate()
{
var multipleEntries = phraseActions.GroupBy(p => p.Phrase).
Where(p => p.Count() > 1).ToList();
if (multipleEntries.Any())
{
var errorMessage = new StringBuilder();
errorMessage.AppendLine(
"Some phrases defined are more than once, this is not allowed");
foreach (var phraseGroup in multipleEntries)
{
errorMessage.AppendLine($"- {phraseGroup.Key}");
}
Debug.LogError(errorMessage);
}
}
Pudding, proof, etc
No code without a demo, as usual. To this end I created this marvelous little script:
public class SpeechCommandExecutor : MonoBehaviour
{
public void DoMoveDown()
{
Debug.Log("DoMoveDown");
transform.position -= Vector3.up * 0.1f;
}
public void DoMoveUp()
{
Debug.Log("DoMoveDown");
transform.position += Vector3.up * 0.1f;
}
}
That moves the game object it is attached to 10 cm up or down, depending on which method is called. I attached this script to three cubes in my scene, then configured a SpeechInputHandler to recognize the phrases “Move up” and “Move down”, and call the appropriate methods on all three cubes.
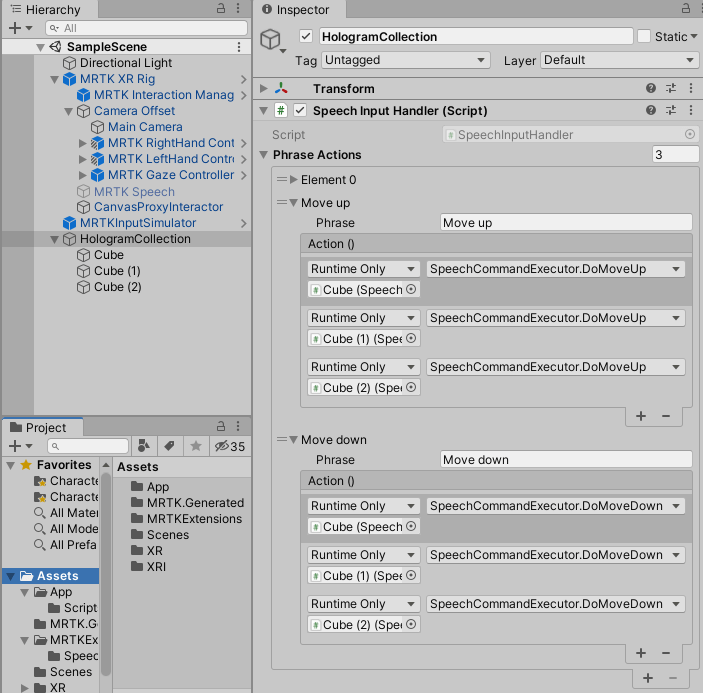
If you don’t mind I am not going to add a movie of myself shouting “move up” and “move down” to show this actually works - it does, and if you don’t believe it, download the demo project and post a movie of yourself testing it yourself, showing that it works. I will add a movie of the first one to do so to this post.
What about Element 0?
Attentive readers might have seen Element 0 is collapsed in the editor. This has no other reason than the fact that Unity QA (who most likely are pretty much understaffed) have missed that in a couple of versions of Unity default editor behavior with lists containing classes is a bit broken. If you expand item 0, you’ll get this:
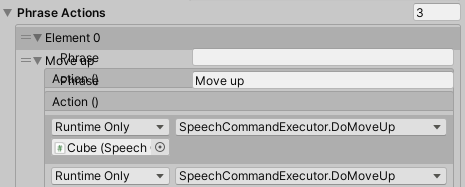
And good luck configuring that. The MRTK3 Interaction Mode Manager configuration suffers from the same bug
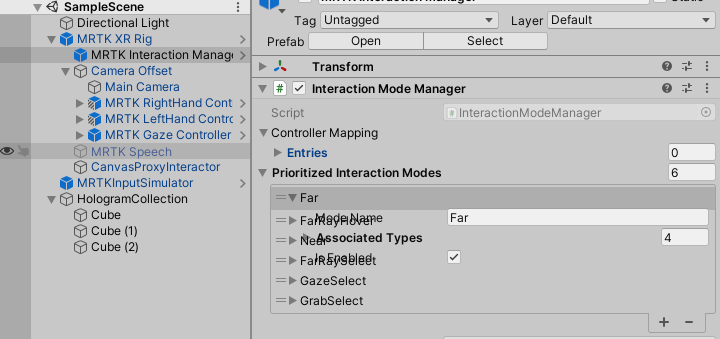
This as also the reason for this line in SpeechInputHandler:
if (!string.IsNullOrEmpty(phraseAction.Phrase) &&
phraseAction.Action.GetPersistentEventCount() > 0)
It’s simply to be able to skip an empty configuration.
Conclusion
After everything is said and done, global speech recognition with MRTK3 is not that hard, especially not with this little helper behaviour. I hope this helps you going forward. Note: speech recognition, for now, works on HoloLens and, with my implementation of a KeywordRecognitionSubsystem, on Magic Leap 2. It also works in the Unity Editor - on Windows, that is.